LinkedIn Post — Analyst Gone Wild Panel (February 2026)
Every AI story we discussed on yesterday’s Analyst Gone Wild panel had one thing in common: the technology was impressive, the outcomes were uncertain, and the missing variable was organizational readiness.
That isn’t a tooling gap. It’s a Phase 0 gap.
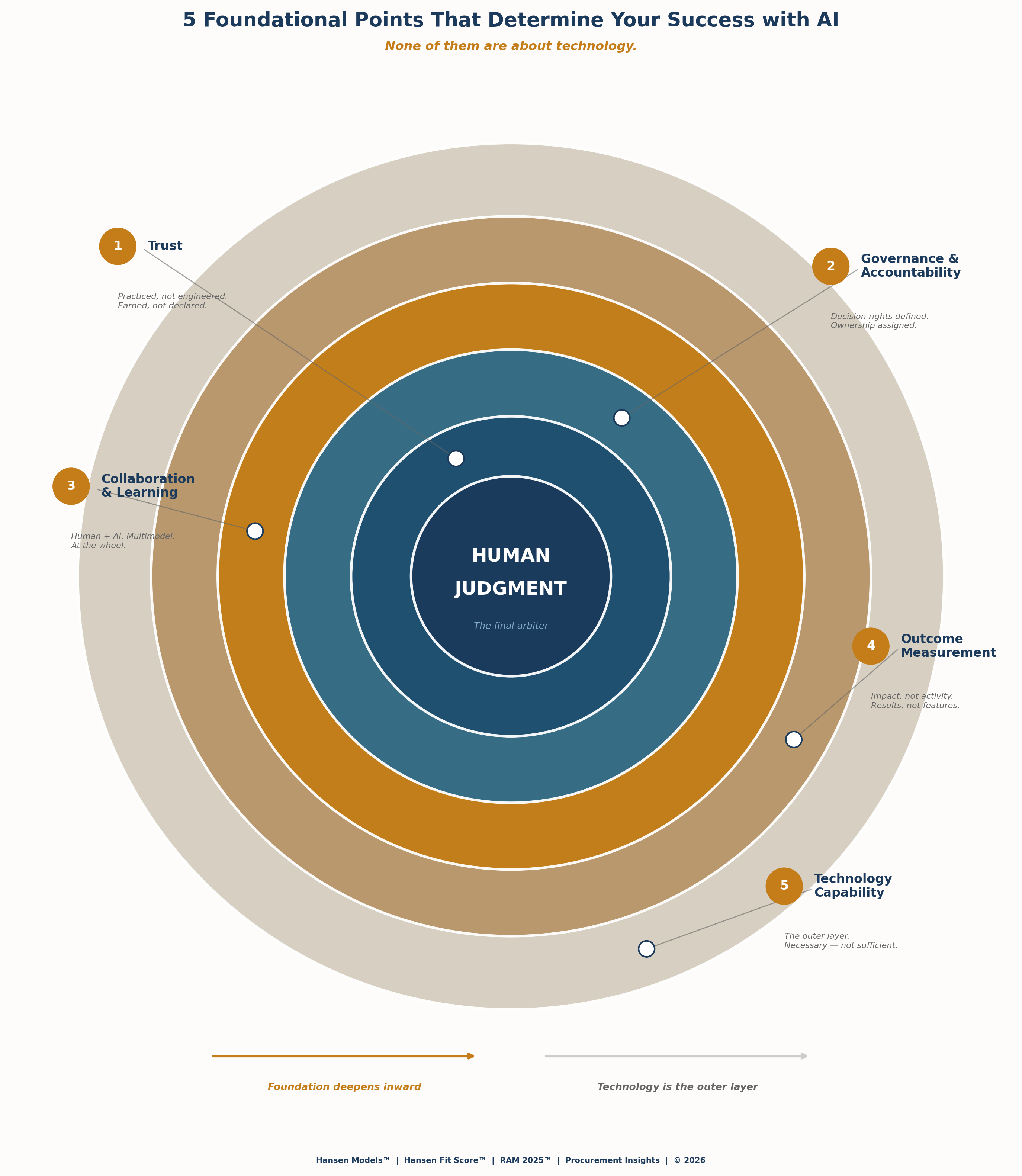
Here are five observations that kept surfacing — across very different AI stories:
1. AI works best when it collaborates — not when it replaces judgment.
Across voice AI, agentic systems, and multimodel approaches, the real breakthroughs came when humans stayed “at the wheel.” Automation without challenge accelerates errors. Collaboration creates learning. I work with multiple AI models simultaneously — sometimes 12 — and they argue with each other because they bring different backgrounds to the same question. But I’m still driving. When I disagree, they sometimes say “you’re right, we missed that.” And sometimes they show me where I’ve been wrong. That’s collaboration. That’s where AI should be heading.
2. Interface innovation is not outcome innovation.
Voice AI may remove screens and keyboards, but it doesn’t remove accountability. Changing how we interact with systems doesn’t change whether organizations are ready to govern them. We can make the interface look like Star Trek — but if the organization behind it hasn’t defined decision rights, the interface is just a faster way to move in the wrong direction.
3. Trust cannot be engineered away — it must be practiced.
“Trust layers” only work when humans are willing to question, challenge, and even override AI outputs. You can build the most sophisticated reinforcement learning pipeline in the world. The final trust layer is still human judgment — not faster training cycles. Task AI and Blend are doing good work. But the trust gap they’re trying to close isn’t a data problem. It’s a human readiness problem.
4. Sovereignty, governance, and control are readiness questions — not architecture choices.
IBM’s digital sovereignty initiative is directionally right. Where data resides matters. But who controls decisions, who approves changes, who monitors outputs, and who is ultimately accountable — those are the questions most organizations haven’t answered yet. You can build the sovereignty architecture. The question is whether the organization is ready to operate it.
5. Capability is accelerating faster than organizational maturity.
Every story highlighted the same pattern: impressive technology moving into environments that haven’t defined decision rights, error handling, or accountability. That gap doesn’t disappear at scale — it compounds. You can build a beautiful Lamborghini. But if nobody has their driver’s license, what good is it?
The real AI trust layer is human — and multimodel.
This is the thread that ties all five observations together. Single-model dependence is structurally fragile. Running multiple models against the same question exposes blind spots, surfaces disagreement, and forces better thinking — like a board of directors with different backgrounds but no ego sitting around the same table. The human sits above that as the final contextual arbiter. Not as a rubber stamp. As the person who questions everything, accepts correction when the models are right, and overrides when they’re wrong.
That’s not a technology architecture. That’s an operating model. And most organizations haven’t built it yet.
The conversation was thoughtful, honest, and worth watching — not because it had answers, but because it surfaced the right questions.
📺 Full panel discussion here: [link to video]
Jon Hansen is the founder of Hansen Models™ and creator of the Hansen Fit Score™. The multimodel approach described above is formalized as RAM 2025™ — Exposed. Explainable. Repeatable.
-30-

Abhinav
February 21, 2026
Point 5 is the one nobody wants to sit with.
Capability accelerating faster than organizational maturity isn’t a technology problem — it’s a governance problem. And governance is unglamorous, slow, and political. Which is exactly why most organizations skip it and wonder why AI deployments underdeliver.
The Lamborghini analogy is fair. But the harder truth is most organizations don’t even know they don’t have a license.
piblogger
February 21, 2026
Abhinav — you just named the deeper problem. The Lamborghini analogy is intentionally simple. The harder truth you’re pointing to is structural: most organizations have no instrument that measures whether they’re ready. Not whether the technology is capable. Whether they are.
That’s the governance gap you’re describing — and it’s the reason the approximately 80% implementation failure rate hasn’t moved in 27 years despite five generations of increasingly capable technology.
The organizations that skip governance aren’t reckless. They simply don’t have a way to measure it before the contract is signed. That’s the gap we’re working to close.
Abhinav
February 22, 2026
That 80% failure rate across 27 years is the stat that should be on every boardroom slide before an AI budget gets approved — but rarely is.
The measurement gap you’re describing is the real problem. Organizations can’t govern what they can’t see, and most don’t build the instrument before the implementation starts.
Curious to know is the Hansen Fit Score designed to be applied pre-contract, or does it typically come in after the first signs of failure?
piblogger
February 22, 2026
Abhinav — that’s exactly the right question, and you’ve put your finger on the core issue: you can’t govern what you haven’t measured yet.
The Hansen Fit Score is designed to be applied pre-contract — before vendor selection, before budgets are locked, and before organizational commitments make course correction politically or financially difficult. That’s what we call Phase 0: measuring organizational readiness and absorptive capacity before technology decisions are made.
That said, in practice we see it used in two ways:
Pre-contract (preferred): as a gating mechanism to determine whether an initiative should proceed at all, and under what conditions. This is where it has the highest predictive and preventive value.
Post-commitment (diagnostic): when early warning signs appear, to identify why outcomes are diverging from expectations and whether recovery is structurally possible — or whether stopping is the responsible move.
Your point about boards is spot on. The persistent failure rate isn’t a technology problem; it’s a measurement problem that shows up as a governance problem. Phase 0 exists precisely because once implementation starts, the most important variables are already invisible — unless you measured them first.
Appreciate the thoughtful comment.