What smoking, procurement, and a logistics podcast have in common
Something happened this weekend that I need to document — not because it was planned, but because it wasn’t.
Within a 48-hour window, three unrelated events converged in a way that demonstrates exactly how Hansen Strand Commonality™ works — and why the methodology behind the Hansen Fit Score™ produces outcomes in the 93–97% longitudinal accuracy range across measured implementation success vs. failure outcomes.
Let me walk you through it.
The Convergence
On Friday, CIO Magazine published an analysis of Salesforce’s new Agentic Work Unit (AWU) metric. Analysts from Moor Insights, Constellation Research, Greyhound Research, and The Futurum Group independently concluded the same thing:
AWU measures activity, not outcomes.
In sharing his article on LinkedIn, the author — Anirban Ghoshal — cited the Hansen Method™ by name alongside those analyst firms.
On Sunday evening, a senior procurement executive I’ve known for over a decade — someone with direct experience across Fortune 500 transformations — sent me a message. Chris Sawchuk, Principal and Global Procurement Advisory Practice Leader at The Hackett Group, had just posted on LinkedIn about agentic AI in procurement. His key phrase: organizations face challenges in “readiness, governance, and team awareness.”
Their note: “I’ve known him 10 years. Never heard him mention readiness before.”
At the same time, in a completely unrelated corner of my feed, Harshida Acharya — a logistics partner and podcast co-host — was writing about delivery and retention. Her observation: “Many leaders make it a priority to experience their own operations directly. Seeing the process as a customer often reveals gaps that metrics alone do not.”
She was describing the 4 o’clock question — the diagnostic moment from our 1998 Department of National Defence engagement — without knowing the term, the methodology, or the history behind it.
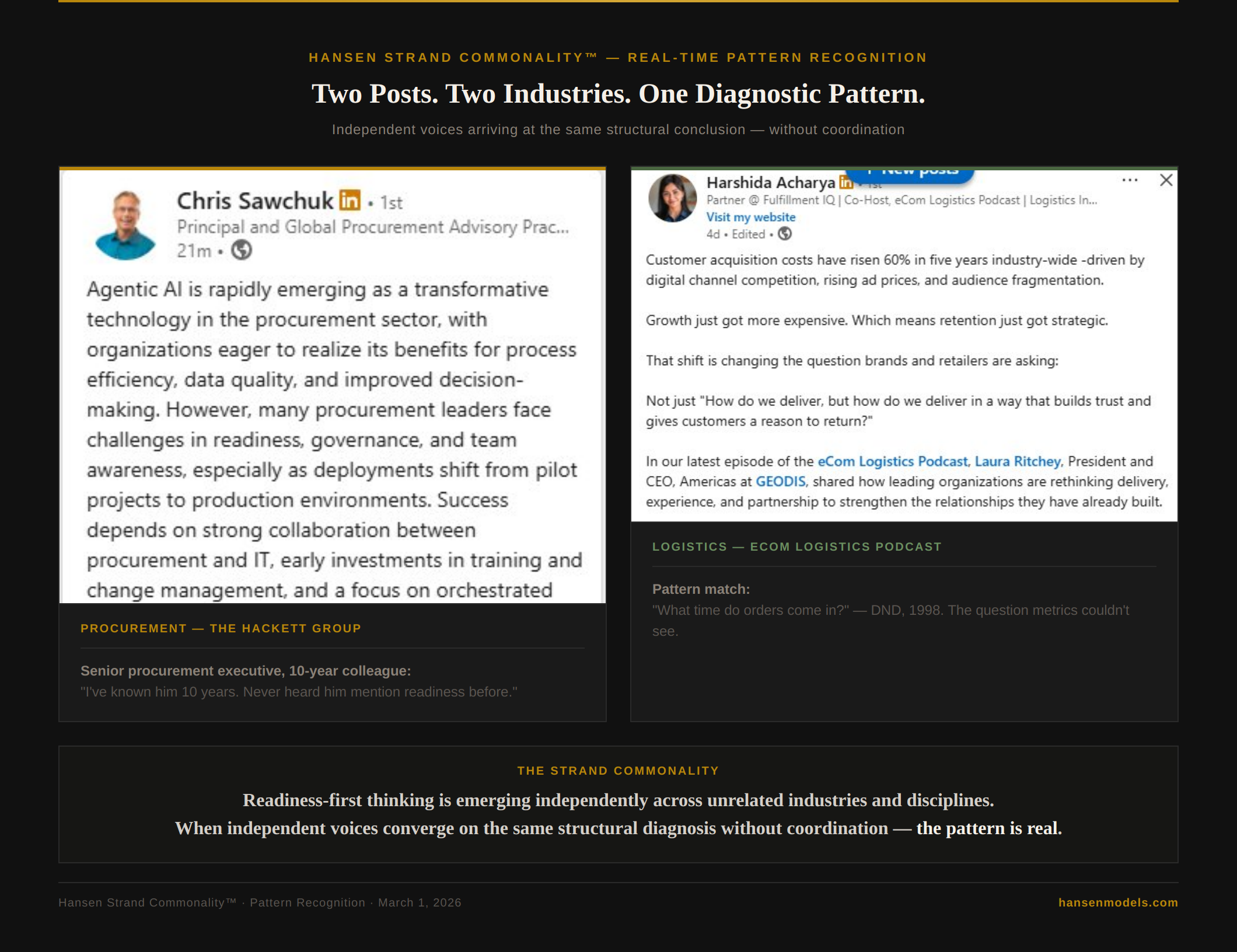
Two posts. Two industries. One diagnostic pattern — emerging independently, without coordination.
That is what strand commonality looks like in real time.
The Longer Pattern
These aren’t isolated signals. They are data points on a trajectory that has been building for four decades — and that the industry has been unable or unwilling to see.
To understand why, it helps to look at the only other modern case where overwhelming evidence failed to change institutional behavior for decades — and what finally broke the pattern.
In 1950, researchers published the first clinical evidence linking smoking to lung cancer. Smoking rates didn’t drop. They increased — peaking at nearly 57% by 1955. It took 14 years for the Surgeon General to issue an official report. It took 48 years for the tobacco industry to concede through the Master Settlement Agreement. It took 75 years for smoking rates to fall from 45% to 10%.
The evidence existed in 1950. The behavior didn’t change until ignoring the evidence became structurally expensive — through litigation, regulation, taxation, and accountability.
Enterprise technology is following the same curve.
Since the early 1980s, implementation failure rates have held at 70–80%. That number has not moved through four decades of technological advancement — not through ERP, not through cloud, not through digital transformation, not through AI. The platforms improved dramatically. The failure rate stayed the same.
During those same four decades, reliance on the instruments designed to guide vendor selection — Gartner’s Magic Quadrant, analyst rankings, capability assessments — increased from near zero to market dominance. And the failure rate held.
The most revealing observation on this timeline is not that the failure rate stayed flat. It is that as instrument reliance increased, outcomes did not improve. The industry didn’t abandon the instrument when it failed to produce results. It doubled down — exactly as public health institutions doubled down on measurement before litigation and regulation finally forced behavioral change in smoking.
What was missing was not better technology, but a diagnostic gate that made starting the wrong initiative more expensive than delaying the right one.
At scale, persistent transformation failure is no longer an operational issue — it is a governance failure.
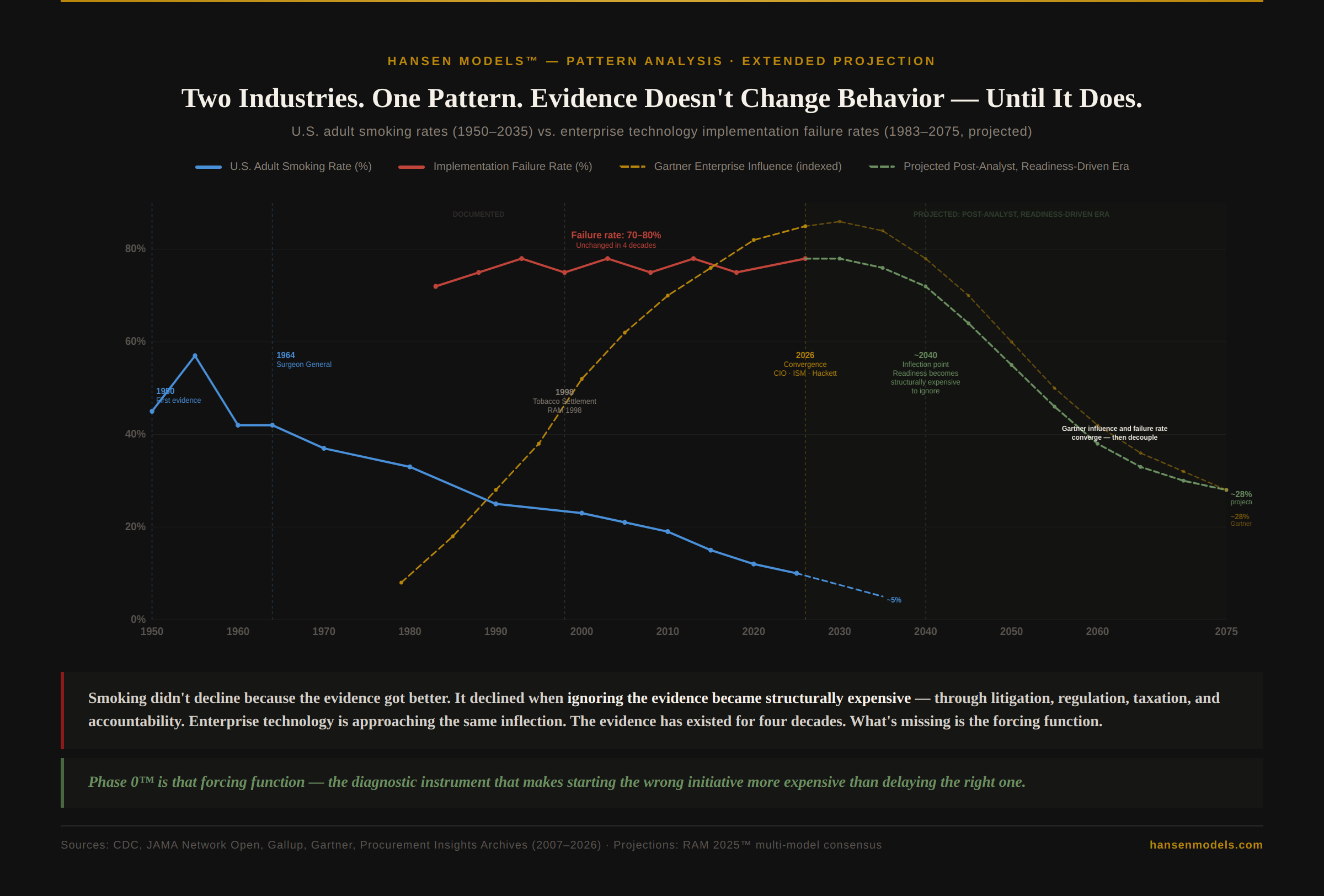
Smoking rates bent only after ignoring the evidence became structurally untenable. Enterprise technology failure rates are approaching that same inflection — and readiness diagnostics like Phase 0™ are the instrument designed to accelerate the decline.
What the Extended Projection Shows
Using the smoking trajectory as a structural analog, RAM 2025™ multi-model consensus projects a three-phase shift:
2026–2035: The plateau. Failure rates hold at 70–80%. The narrative shifts to “AI is different.” The reality is the same decision structures producing faster failure. Gartner-style influence peaks and begins to flatten. This is the industry’s pre-Surgeon General period — the evidence is now public, the convergence is happening, but institutional behavior hasn’t changed yet.
2035–2050: The inflection. Variance increases. Early adopters of readiness-first diagnostics begin separating from the pack. Regulatory pressure on AI governance, board-level accountability for transformation failures, and accumulated evidence from documented Phase 0™ outcomes create the forcing function. Failure rates begin their structural decline — not because technology improves, but because ignoring readiness becomes financially and operationally untenable.
2050–2075: The readiness era. The analyst ecosystem doesn’t disappear — it repositions as one input among many, rather than the dominant instrument. Readiness-first diagnostics replace capability-first rankings as the primary decision architecture. Failure rates decline to approximately 28% — never zero, because organizational behavior is structurally stickier than individual habits. But less than half of where they sat for four decades.
Why This Matters Now
Phase 0™ is not predicting the future. It is diagnosing the present — using a methodology built on government-funded research (Canada’s SR&ED program, 1998), maintained through the most comprehensive independent practitioner-provider archive in the industry (Procurement Insights, 2007–present, 3,300+ published documents), and stress-tested through five independent AI models in structured dissent.
The strand commonality identified this weekend — Chris Sawchuk using readiness language for the first time in 10 years, a logistics professional independently describing diagnostic-first thinking, CIO Magazine article author citing the Hansen Method™ alongside major analyst firms in his LinkedIn post — is not a coincidence. It is the convergence point on the timeline, happening in real time.
The evidence against enterprise implementation failure has existed for four decades. What’s missing isn’t data — it’s a forcing function that makes ignoring it impossible.
Phase 0™ is that forcing function.
Smoking didn’t decline because the evidence got better. It declined when the cost of ignoring it exceeded the cost of acting on it.
The enterprise technology industry is approaching the same inflection.
Hansen Models™ · Jon Hansen, Founder · HPT@HansenProcurement.com Independent since 1998 · No vendor funding · No referral fees · No implementation revenue
-30-

Tim Cummins
March 2, 2026
perhaps a significant contributor to failure rates is that technology is being applied to a faulty operating model. ERP ossified that model. AI creates an opportunity for fresh thinking and could generate quite different results – but it could also fall victim to the established model, eliminating much of its potential.
I prefer to be optimistic. AI is different from traditional enterprise technology because it is not dependent on deep pockets. Small businesses and start-ups will deploy it as a foundation for growth, demonstrating that it disrupts traditional ways of organising and managing a business.
piblogger
March 2, 2026
Tim — I agree with you that a faulty operating model has been a major contributor, and ERP certainly ossified more than it transformed. And I share your optimism that AI creates an opportunity for fresh thinking — particularly outside the largest enterprises.
One dynamic that may accelerate that shift is the SME segment. Unlike previous technology waves, many small and mid-sized businesses now have the financial and technical access to engage directly with AI-native ProcureTech providers. That changes the competitive math.
It reminds me somewhat of the MAI Basic Four and Industry Specific Applications era. The disruption didn’t begin by replacing the dominant players at the top — it began by serving segments the incumbents weren’t structurally designed to prioritize. Over time, that shifted the center of gravity.
The open question is whether large enterprises will use AI to redesign their operating models intentionally — or whether the redesign will happen externally first, driven by smaller, more adaptive organizations.
AI absolutely can generate different results. But history suggests that whether it does depends less on the technology and more on whether leaders are willing to change the operating model before scale locks it in again.
tcummins
March 2, 2026
We are seeing positive examples where large corporates not only ‘get it’. but are taking action. I’m enthused by some of what I see and hear – and we will be reporting on it as much as confidentiality allows us. The fear is always that internal resistance will derail the intent: management structures and functional interests have a remarkable ability to resist, even when it damages their own long-term interests.
piblogger
March 2, 2026
Tim — I’m encouraged to hear this, and I agree that it’s important to document the cases where large organizations not only understand the issue but are acting on it. Those examples matter, especially because they demonstrate that scale itself is not the barrier.
Your caution about internal resistance is well placed — and I’d go a step further. In my experience, that resistance is rarely irrational or malicious. It’s usually structural. Management layers and functional interests resist because the operating model was never designed to redistribute judgment, accountability, and consequence safely. When those elements are ambiguous, self-protection becomes a rational response, even if it undermines long-term outcomes.
This is where I think the real distinction lies between intent and durability. Many organizations genuinely want to change. Fewer have redesigned governance, decision rights, and escalation paths deeply enough for that intent to survive contact with operating pressure. When resistance appears, it’s often treated as a cultural problem — but more often it’s a signal that the structure hasn’t been made fit for the change it’s being asked to carry.
The positive cases you’re seeing, I suspect, are the ones where leaders anticipated this dynamic early — not just by sponsoring AI or transformation initiatives, but by explicitly redesigning the operating model so that distributed judgment could function without penalizing the people expected to exercise it.
If that’s right, then resistance isn’t the enemy — it’s the early warning system. The organizations that listen to it diagnostically have a chance to convert intent into sustained outcomes. The ones that don’t tend to rediscover, once again, that evidence alone doesn’t change behavior — until the structure makes it safe to do so. I suspect this is also why many AI initiatives that succeed in pilot form never gain wider enterprise adoption.