By Jon W. Hansen | Procurement Insights
SHORT VERSION: For executives who need the conclusion first.
In 1983, Peter Kraljic described a procurement world defined by volatility, independent actors, and patterns that could be “upset virtually overnight.” Then he gave the industry a static 2×2 matrix. The diagnosis was agent-based. The instrument was equation-based. Every major framework since — Porter, O’Brien, RAQSCI, Cullen — made the same category error: acknowledged complexity, then delivered a portable tool that assumes stability. Four decades later, the failure rate is still 50–80%. The frameworks are not failing because they are invisible. They are failing because they are equation-based models applied to agent-based problems. The Hansen Fit Score™ is designed to do what Kraljic’s own observation called for: monitor the agents continuously, read the full longitudinal record, and submit every prediction to public, falsifiable accountability. Kraljic saw the world we model. We have built the longitudinal instrument that his diagnosis deserved.
A LinkedIn exchange last week surfaced a question worth exploring beyond a comment thread.
A procurement professional — a director of global strategic sourcing — challenged the Hansen Fit Score™ methodology on what he considered a transparency issue. His argument: the best procurement frameworks he has worked with — Kraljic, O’Brien’s 5i, Cullen’s contract scorecards — gain credibility from visible mechanics. You can pick them up, stress-test them, adapt them independently. The Fit Score, he argued, operates as a “trust-the-expert” model, not a “visible-mechanics” model.
Fair challenge. And he is right about the distinction. However, the assumption that visible mechanics are sufficient for the problem being solved is what today’s post will address.
The Quote That Contradicts the Matrix
In 1983, Peter Kraljic published his landmark Harvard Business Review article, Purchasing Must Become Supply Management. The matrix he introduced has endured for over four decades. It is taught in every procurement program, embedded in every consulting methodology, and referenced in virtually every vendor’s sales deck. It deserves its place in the field’s intellectual history.
But read Kraljic’s own framing of the problem:
“The stable way of business life many corporate purchasing departments enjoy has been increasingly imperiled. Threats of resource depletion and raw materials scarcity, political turbulence, and government intervention in supply markets intensified competition and accelerating technological change have ended the days of no surprises. As dozens of companies have already learned, supply and demand patterns can be upset virtually overnight.” – Peter Kraljic (1983)
Count the agents in that single paragraph. Resource depletion. Raw materials scarcity. Political turbulence. Government intervention. Intensified competition. Accelerating technological change. Supply and demand disruption. Seven independent variables, each operating on its own timeline, each capable of triggering nonlinear effects on the others.
“Upset virtually overnight.” Kraljic himself is telling you the system does not trend toward equilibrium. It ruptures.
And then he gave the industry a four-quadrant box with two axes.
The Category Error
This is not a criticism of Kraljic’s intelligence. The man saw the problem with extraordinary clarity. It is a criticism of the instrument design tradition he was working within.
In 1983, the available modeling paradigm was equation-based: define your variables, plot your position, derive your strategy. Agent-based modeling as a computational discipline barely existed. Kraljic described an agent-based world because that is what he observed. He built an equilibrium tool because that is what the era had to offer.
The problem is that the industry never upgraded the instrument.
Every framework that followed — Porter, O’Brien, RAQSCI, the ones my LinkedIn challenger cited — made the same structural choice. They acknowledged complexity in their introductions and then delivered structured, portable tools that assume enough stability to be universally applicable. The diagnosis was always right. The instrument design never matched.
Four decades of visible-mechanics frameworks. Four decades of 50–80% implementation failure rates. The frameworks are not failing because they are invisible. They are failing because they are equation-based models applied to agent-based problems.
I was asking this question publicly before the Hansen Fit Score™ vendor assessments even launched. In July 2024, I published 41 Years Later, Is the Kraljic Matrix Still Valid? — not to dismiss Kraljic, but to ask whether any static framework, however elegant, can survive contact with the volatility its own creator described.
42 Years of Frameworks. One Unchanged Failure Rate.
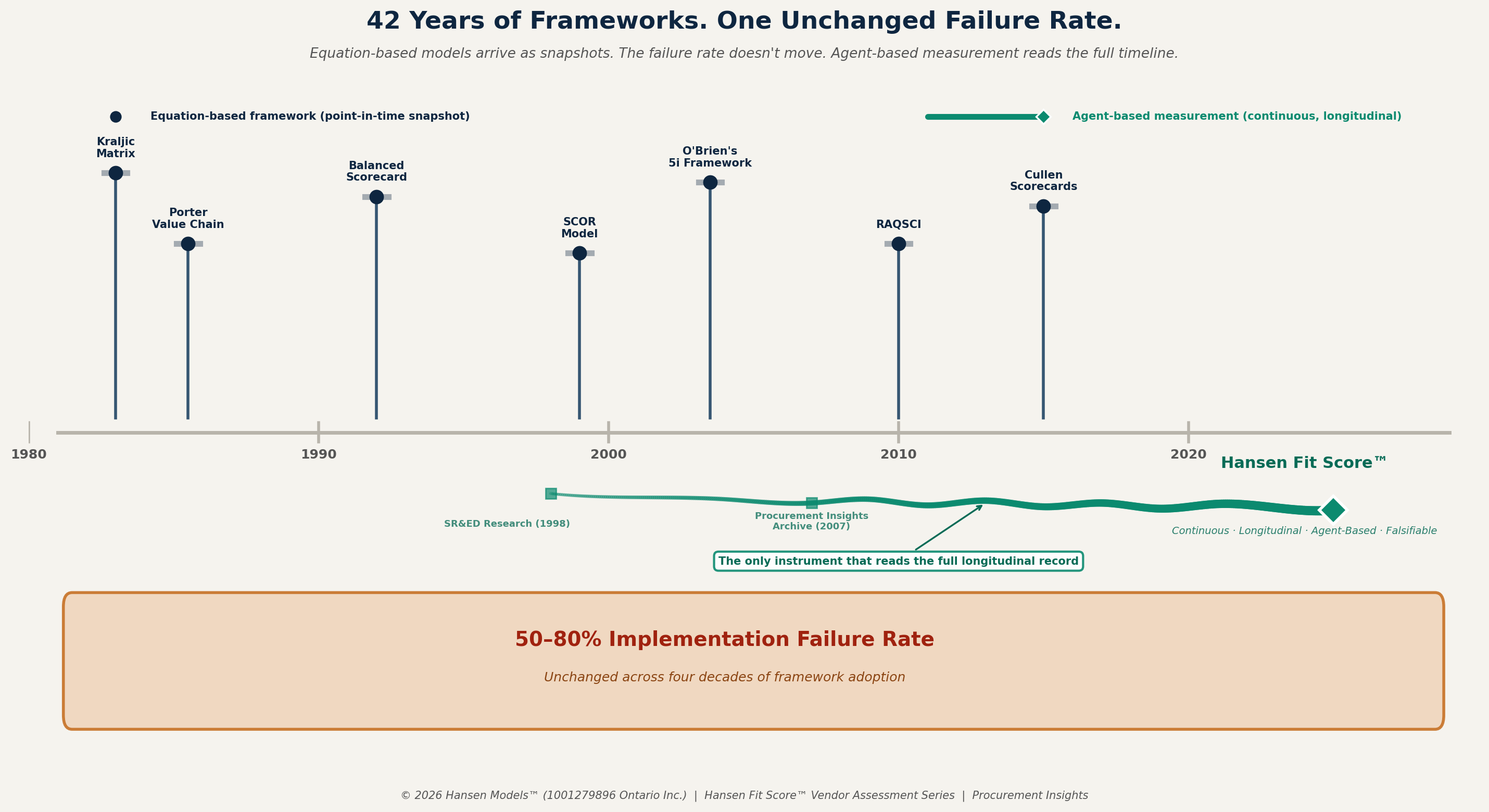
Equation-based models arrive as snapshots — frozen at publication. The failure rate doesn’t move. Agent-based measurement reads the full timeline.
The graphic above tells the story that four decades of conference keynotes have not. Every major procurement framework appears as a pin on the timeline — a point-in-time contribution, frozen at the moment of publication. Below them, the 50–80% implementation failure rate runs unbroken across the entire span. Not one of those frameworks moved it.
The Hansen Fit Score™ is the only instrument that reads backward through the full longitudinal record — from the SR&ED-funded research in 1998 through the Procurement Insights archive beginning in 2007 to the present-day vendor assessments. The difference is not intellectual superiority. It is instrument design. Snapshots categorize. Longitudinal measurement tracks the agents as they actually move.
The distinction between equation-based and agent-based approaches is not new to this analysis. I first documented the framework in a 2005 paper, and published the full argument — including why equation-based models produce the failure rates the industry continues to report — in Similarity Heuristics, Iterative Methodologies and the Emergence of the Modern Supply Chain in April 2008. The analogy I used then still holds: equation-based models are painters trying to capture a moving subject on canvas. No matter how skilled the artist or how advanced the tools, the subject won’t hold still. Agent-based models are camcorders — they capture the movement in real time. Kraljic described the moving subject in 1983. The industry has been erroneously improving canvases ever since.
Agent-Based Problems Require Agent-Based Instruments
Implementation readiness is not a portfolio segmentation exercise. It involves vendor structural risk, ownership dynamics, PE acquisition cycles, leadership churn, platform integration behavior, and longitudinal outcome patterns across multiple technology generations. The variables are not finite, and the environment is not controlled. The actors — vendors, investors, executives, regulators — make independent decisions that reshape the landscape in ways no static axis can capture.
The Hansen Fit Score™ does not try to compress that volatility into a portable matrix. It monitors the agents and continuously re-measures as they move. When a PE firm acquires a vendor and replaces the entire C-suite in nine months, that is not a data point on an axis. It is a structural event that changes the risk profile for every practitioner on that platform. The instrument has to move with it.
This is the design choice my LinkedIn challenger identified correctly: the Fit Score is a documented, accountable judgment model, not a pick-up-and-use framework. That is by design, not by default. The complexity of the problem demanded it.
The Trust Proposition
But here is where the conversation gets interesting. My challenger argued that visible-mechanics models earn trust because anyone can independently evaluate them. The implication is that a judgment-based model asks you to trust the physician without being able to examine the method.
I would rather get it right than be right.
There is no such thing as infallibility without ongoing verification. That is where RAM 2025™ comes in. The scores are not static. RAM 2025™ continuously loops real-world outcomes back through multiple AI models across five validation levels — not to confirm prior judgments, but to challenge them. The methodology is built on the assumption that the last score could be wrong. Every assessment is an invitation to falsify the previous one.
And the verification is public.
In February 2025, James Meads of The Procurement Software Podcast publicly disagreed with my prediction that 75% of ProcureTech solution provider logos would disappear. He put his own number on the line: 20–25% net consolidation. Fair challenge. I respected him for making a counter-prediction publicly.
So we went back and measured. Not to defend the claim — to test it.
Predicted: 75%. Measured: 72%. James predicted 20–25%. The archive — timestamped, public, falsifiable — settled it.
That is the trust proposition. Not “trust me.” Watch the predictions meet the data over time.
Kraljic has been visible for 42 years. Anyone can pick it up, stress-test it, adapt it. And the implementation failure rate has not moved. No one has ever held that framework accountable for outcomes, because the framework was never designed to produce them. It was designed to categorize.
The Hansen Fit Score™ is designed to predict. And predictions have a built-in accountability mechanism that categorization does not: they can be wrong. Publicly. Measurably. The archive is the audit trail.
What Would Kraljic Say?
I have thought about this more than once.
Peter Kraljic looked at the procurement landscape in 1983 and saw what most of his contemporaries did not — a system defined by independent actors, nonlinear disruption, and patterns that could be “upset virtually overnight.” He saw an agent-based world. He described it with precision that still holds four decades later.
He built the best instrument the era allowed. A static matrix was the available technology for strategic thinking in 1983, just as mainframes were the available technology for data processing. No one faults the mainframe for not being a neural network. The contribution was real, and it endured for good reason.
But I believe Kraljic would have been the first to say that his matrix was a starting point, not a destination. His own language demanded something more — an instrument that could move with the agents it described, that could trace patterns across decades rather than freezing them at a single moment, that could hold itself accountable to outcomes rather than just categorization.
I do not know what Peter Kraljic would say about the Hansen Fit Score™. But I know what his 1983 diagnosis called for: an instrument that treats volatility as the operating condition, not the exception. A model that reads longitudinally rather than cross-sectionally. A methodology that submits itself to the same falsifiability standard it applies to the vendors it assesses.
His quote described the world we model. We have built the instrument that his diagnosis deserved.
The Hansen Fit Score™ Vendor Assessment Series is available through Hansen Models™. Individual assessments are $1,750 US each. Annual subscription access to the full library is $3,000 US.
-30-

Dean S
February 24, 2026
This is a stronger argument than the original article, Jon, and I appreciate you developing it seriously. The Kraljic observation cuts deep — agent-based description, equation-based instrument. That tension is real. And vendor survivability as an evaluation dimension is underweighted in most procurement frameworks.
Where I’d push back: the equation-vs-agent framing holds only if you treat O’Brien’s 5i and Cullen’s scorecards as static snapshots. They’re not. The 5th i is explicitly a continuous feedback loop, and Cullen’s scorecards are designed for periodic recalibration. Iterative isn’t agent-based — but it’s not “equation frozen at publication” either. The binary flattens a more interesting spectrum.
And the 75%→72% prediction — impressive as market knowledge — tests a different claim than the Fit Score’s 85-97% implementation success rate. One measures whether you understand consolidation patterns. The other measures whether the instrument improves practitioner outcomes. Only the first has been publicly verified so far. They’re not competing metrics — they’re measuring different things. You’ve moved the argument forward from where it started, and the vendor survivability lens deserves more development from the field. Congrats!
piblogger
February 24, 2026
Dean — this is a thoughtful pushback, and I appreciate the precision of it.
You’re right on one important point: O’Brien’s 5i and Cullen’s scorecards are not frozen snapshots. The feedback loops and recalibration mechanisms you cite absolutely matter, and they move those frameworks well beyond Kraljic’s static matrix. The binary I drew flattens a more interesting spectrum, and you’re right to call that out.
Where I still draw the line between iterative and agent-based is in what the model is allowed to notice.
Even with feedback loops, iterative frameworks tend to recalibrate within predefined variables and bounded questions. They refine what is already considered relevant. Agent-based approaches expand what is allowed to become relevant in the first place — including factors that were not scoped, anticipated, or even considered “in bounds” at the outset. I’d call that the fluidity of inclusive thought — the willingness to look beyond the model’s own boundaries for variables the model doesn’t know it’s missing. That’s the line on the spectrum that matters: not static vs. iterative, but bounded recalibration vs. unbounded discovery.
A concrete example from my own work: in a government MRO procurement operation achieving 51% next-day delivery against a 90% contractual target, the turning point wasn’t optimizing a known variable. It was asking a question no framework prompted: what time of day do orders actually come in?
The answer — 4 PM — revealed an entire ecosystem of failure drivers that existed outside every framework’s parameter set: service technicians sandbagging orders to maximize daily call counts, dynamic flux pricing that penalized late-day orders by hundreds of dollars per unit, small suppliers with no customs clearance sophistication, and a courier integration gap that compounded every delay. None of these lived inside the procurement process. All of them determined the procurement outcome.
An iterative scorecard would have recalibrated the delivery metrics periodically. It would never have generated that question, because order timing wasn’t one of its parameters. The result once those agents were identified and addressed: 51% to 97.3% next-day delivery. Not by optimizing the existing process, but by discovering the behavioral strands the process map couldn’t see.
Your second point on metrics is also fair, and it connects directly to the first. The 72%–75% consolidation validation and the implementation outcomes are not the same claim. One is market truth detection — can the methodology identify structural patterns before the market confirms them? The other is execution consequence avoidance — can it improve practitioner outcomes when those patterns are operationalized into decision gating? You’re right that only the first has been publicly verified at scale so far.
But the bridge between them is precisely the capability the DND example demonstrates: the methodology’s ability to surface the “out-of-scope” questions that bounded frameworks don’t generate. That’s what produced the 97.3%. And that’s what the Hansen Fit Score™ vendor assessments are building the public, falsifiable record to verify or refute over time at the market level.
I don’t think we’re discussing whether the classic frameworks are valuable — we’re discussing whether they are sufficient for the level of volatility practitioners are now exposed to. That’s the right discussion to have.
Appreciate you raising it, Dean. This exchange has been more productive than most conference panels I’ve sat on.